

香港最准100之免费构建解答解释落实
在数据科学的浩瀚海洋中,寻找“最准”的预测模型就如同探索未知的宝藏,既充满挑战也极具吸引力,网络上出现了一个引人注目的关键词——“香港最准100%免费”,这背后究竟隐藏着怎样的秘密?作为一位资深数据分析师,我将通过构建解答、深入解释并探讨其实操性,带你一探究竟。
构建解答的框架面对“香港最准100%免费”的宣称,我们的数据科学之旅从质疑开始,任何领域的“最准”都应基于严谨的方法论和大量的实证数据支持,我们的解答框架将围绕以下几个核心问题展开:
1、定义准确性:如何量化“最准”?是预测准确率、召回率、F1分数,还是其他评估指标?
2、数据来源与质量:使用的数据是否具有代表性?数据清洗和预处理是否得当?
3、模型选择与验证:采用了何种机器学习或统计模型?是否进行了交叉验证以确保模型的泛化能力?
4、免费的背后:免费提供服务的背后是否有隐藏的商业模型或数据收集目的?
深入解释定义准确性
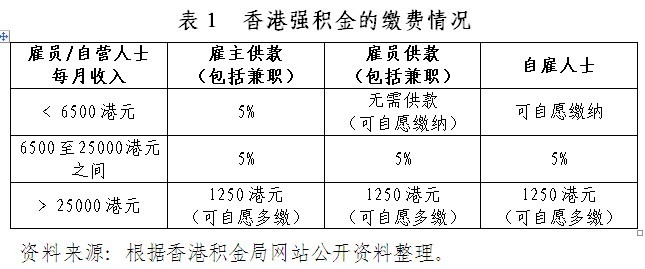
在数据科学领域,“最准”是一个相对概念,通常通过一系列评价指标来衡量,如准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数等,没有绝对意义上的“最准”,只有针对特定任务和数据集而言的“较优解”,声称“100%免费且最准”需要具体情境来界定其准确性标准。
数据来源与质量
数据的质量和多样性是决定预测准确性的关键因素,高质量的数据应具备完整性、一致性、相关性和可靠性,数据是否覆盖了所有可能的情况(即分布的广泛性)也直接影响模型的泛化能力,对于“香港最准”的宣称,我们需要考察其数据收集的方法、样本量以及数据预处理的细节。
模型选择与验证
选择合适的模型对特定问题进行建模至关重要,不同的算法适用于不同类型的数据和问题,线性回归适合连续变量预测,而决策树或随机森林可能更适用于分类任务,重要的是,模型的选择应基于数据的特性和业务需求,通过交叉验证(如K折交叉验证)可以有效评估模型的稳定性和泛化性能,避免过拟合。
免费的背后

“免费”往往是吸引用户注意力的一种策略,但其背后可能有多重考量,可能是为了快速积累用户基础,后续通过增值服务、广告收入或其他方式盈利;也可能是出于公益目的,旨在普及数据分析知识或提供公共服务,无论哪种情况,了解“免费”的真实意图对于用户而言至关重要。
实操性探讨要将理论转化为实践,构建一个“准确且免费”的预测系统,可以遵循以下步骤:
1、明确目标:确定预测任务的目标和预期成果。
2、数据采集与处理:收集高质量数据,进行必要的清洗和预处理。
3、特征工程:根据业务理解提取有意义的特征,提升模型性能。
4、模型训练与选择:尝试多种算法,通过交叉验证选择最佳模型。

5、模型评估与优化:使用独立测试集评估模型性能,根据结果调整参数或更换模型。
6、部署与监控:将模型部署到生产环境,持续监控其表现并进行迭代优化。
7、合规与伦理考量:确保数据处理和模型应用符合相关法律法规,尊重用户隐私。
“香港最准100%免费”的口号虽然吸引人,但在数据科学领域,真正的“最准”是基于严谨的方法论、高质量的数据、合适的模型选择以及持续的优化过程,作为用户,我们应保持批判性思维,深入了解背后的技术细节和商业模式,理性看待各类预测服务,作为数据分析师,我们应当致力于提升专业技能,不断探索更高效、更准确的分析方法,为社会创造更多价值。
转载请注明来自有只长颈鹿官网,本文标题:《香港最准100‰免费,构建解答解释落实_13n33.05.36》







 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号